Note
Support for UNICODE_VERSION environment variable will likely be removed, please disregard this article. See https://github.com/jquast/wcwidth/issues/104 for more details.
Quicktro
The printable length of most characters are equal to the number of cells they occupy on the screen: 1 character : 1 cell. However, there are categories of characters that occupy 2 cells (full-width), and others that occupy 0 cells (zero-width).
All popular terminals support displaying full and zero-width Unicode characters correctly. For CLI applications and their libraries, such as IPython and python-prompt-toolkit, it is just a matter of calling into the python wcwidth library when rendering characters for display, albeit with a small bit of care around the occasional -1 return value.
The Problem
If this is a solved problem, why do we still see so many misaligned characters in Terminal applications?
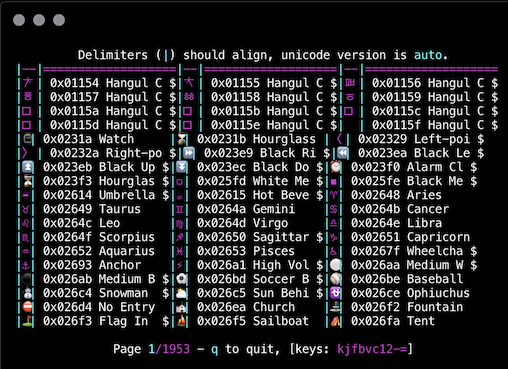
At this time of writing, each Unicode version, 4.1, 5.1, 5.2, 8.0, 9.0, 10.0, 11.0, 12.0, 12.1, and 13.0, have support for more full and zero-width characters than their previous version, with many more versions expected to be released in the coming years.
Chinese, Japanese, and Korean users, whose languages use full-width characters have been the most impacted by this problem. The Western world only seemed to notice it with the introduction of emoticons in Unicode version 9.0.
Terminal and library authors select only one version of Unicode when they implement zero and full-width support. Sometimes, the latest specification is used, but usually not. Most just copy any existing solution without too much care, and we can't really blame them, it's actually a pretty difficult decision.
iTerm2, for example, makes great care for Unicode support, but supports only version 8.0 unless the check box, "Use unicode version 9+ widths" is enabled (12.1.0 at time of this writing). The choice to use 8.0 by default is likely made to match the libc version linked by most C/C++ Terminal apps that include wchar.h from the standard C library. On Mac OS X 10.11.5 and newer, this is also version 8.
Many 3rd party applications and languages conform to only Unicode 5.0 (such as hyper terminal in the above figure), which happens to be the version of Unicode in the wcwidth.c file released by Markus Khun into the public domain in 2007 from which almost all implementations are duplicated from.
Problem statement
The version of Unicode used by Terminals and Libraries will continue to be a problem, because new versions of the Unicode Standard are issued periodically, but the source code of libraries and applications are not updated at the same time, or at all!
The wcwidth.c family of libraries in use cannot know what version of Unicode your terminal supports, and the terminal cannot know what version an application intends to use.
The Solution
In the python wcwidth library, I added support for all versions of Unicode, it requires only a matter of selecting the right version, by function argument, or, by environment variable, UNICODE_VERSION.
But how can we know what version is used? Well, I do hope other language implementations of wcwidth() and wcswidth() can follow my example of multi-version and selection support by the environment UNICODE_VERSION, and, that terminal emulators can export their supported version by environment value.
But this is going to take some time, perhaps only by my own volunteer efforts, which is probably a lot more in discussion and education than code. So, this article is my first attempt at starting those discussions.
I've authored another tool, ucs-detect, which is able to automatically detect the version of unicode that the connecting Terminal supports. For any application using the python wcwidth library, the correct return value is selected by using the given value of the UNICODE_VERSION environment variable.
With this solution, we can correctly determine the UNICODE_VERSION of hyper terminal as 5.1.0, and those cells that were previously thought to be full-width, are now correctly determined to be half-width by the wcwidth python library, and align correctly:
For developers who work on this stuff, please take a look at the ucs-detect and wcwidth documentation for a more complete description of how this all works. I would like to see this solution adapted to more shells and CLI apps until Terminal emulators and libraries can be persuaded.
The standard C library in particular is very unlikely to adopt, and only after many several years if it does. Luckily for us, modern Terminal applications are rapidly developed in dynamic languages where such changes can be much more quickly propagated.
Interim
Download and install ucs-detect, and add to your shell profile:
if [ -z "$UNICODE_VERSION" ] && command -v ucs-detect >/dev/null; then
eval "$(ucs-detect)"
fi
While I have your attention
If you're reading this, you must have some level of interest in Terminals, so if you are not aware of the continued, unrelenting, voluntary contributions to the Terminal ecosystem by Thomas E. Dickey, please take a moment to have a look at his website.
Of particular interest to me, at least, is the documented trials and tribulations of developing ncurses. I like to think that a lot of the software engineering work we come into contact with each day would have happened eventually, no matter who did it. But Thomas E. Dickey is one of those exemplary folks who have the discipline to solve the smallest and most difficult problems that can add up to the greatest change. Every engineer should have at least 1 role model, and Mr. Dickey is one of mine.